
혼자 공부하는 SQL
| # | 진도 | 기본 미션 | 선택 미션 |
| 1주차 (1/2 ~ 1/7) |
Chapter 01 ~ 02 | p. 80의 shop_db의 회원 테이블(member)에서 아이유 회원에 대한 정보만 추출한 후 결과 화면 인증하기 | 데이터베이스 개체 3가지 설명하기 |
| 2주차 (1/8 ~ 1/14) |
Chapter 03 | p. 138의 확인 문제 2번 풀고 인증하기 | 데이터 입력, 삭제하는 기본 형식 작성하기 |
| 3주차 (1/15 ~ 1/21) |
Chapter 04 | p. 195의 확인 문제 4번 풀고 인증하기 | p. 183 [좀 더 알아보기] 손코딩 실행하고 결과화면 인증하기 |
| 4주차 (1/22 ~ 1/28) |
Chapter 05 | p. 226의 market_db의 회원 테이블(member) 생성하고, p. 229 데이터 입력한 후 인증하기 | p. 271 확인 문제 4번 풀고 인증하기 |
| 5주차 (1/29 ~ 2/4) |
Chapter 06 | p. 310 인덱스 생성하고 key_name이 PRIMARY로 출력된 결과 화면 캡처하기 | 인덱스 생성, 제거하는 기본 형식 작성하기 |
| 6주차 (2/5 ~ 2/12) |
Chapter 07 ~ 08 | p. 363 market_db의 고객 테이블(member)에 입력된 회원의 정보가 변경될 때 변경한 사용자, 시간, 변경 전의 데이터 등을 기록하는 트리거 작성하고 인증하기 | p. 402 GUI 응용 프로그램 만들고 인증하기 |
이번 주 진도
| # | 진도 | 기본 미션 | 선택 미션 |
| 5주차 (1/29 ~ 2/4) |
Chapter 06 | p. 310 인덱스 생성하고 key_name이 PRIMARY로 출력된 결과 화면 캡처하기 | 인덱스 생성, 제거하는 기본 형식 작성하기 |
4주 차에 우수 혼공족이 되어 간식도 먹었으나... 이번 주 따라 무기력해서 일요일이 되어서야 완료를 하였다.
이제 다음 주가 마지막인데 7, 8 챕터 두 개나 해야 해서 과연 힘낼 수 있을지 모르겠다 ㅋㅋㅋ
SQLD는 일단 신청해보긴 했다. 아직 한 달 남았으니까 어떻게든 되겠지!
기본 미션
p. 310 인덱스 생성하고 key_name이 PRIMARY로 출력된 결과 화면 캡처하기

선택 미션
인덱스 생성, 제거하는 기본 형식 작성하기
- 생성
CREATE [UNIQUE] INDEX 인덱스_이름
ON 테이블_이름 (열_이름) [ASC | DESC]
- 제거
DROP INDEX 인덱스_이름 ON 테이블_이름
정리
06 - 1 인덱스 개념을 파악하자
1. 인덱스란
- 인덱스는 책의 찾아보기 섹션과 비슷하다. 필요한 데이터를 빠르게 찾을 수 있도록 해주는 도구이다.
- 인덱스가 많다고 해서 무조건 좋은 건 아니다. 필요 없는 인덱스를 만들면 찾는 시간이 오히려 더 길어진다.
- 인덱스의 장점: 기존보다 아주 빠른 응답 속도를 얻어 결과적으로 전체 시스템의 성능이 향상된다.
- 인덱스의 단점: 데이터베이스 안에 추가적인 공간이 필요하다. 처음 인덱스를 만드는 시간이 오래 걸릴 수 있다.
2. 인덱스의 종류
- 클러스터형 인덱스(Clustered Index): 영어사전. 테이블을 만들면 기본 키 열에 클러스터형 인덱스가 자동으로 생성된다. 즉 클러스터형 인덱스는 테이블에 한 개만 만들 수 있다.
인덱스를 확인하는 법: SHOW INDEX FROM 테이블_이름
클러스터형 인덱스는 기본 키를 기준으로 자동으로 정렬시킨다.
mem_id를 기본 키로 지정하였더니, 입력 순서와 관계없이 ABCD 순으로 정렬된 것을 확인할 수 있다.
- 보조 인덱스(Secondary Index): 찾아보기. 고유 키 열에 보조 인덱스가 자동으로 생성된다. 즉 보조 인덱스는 테이블에 여러 개 만들 수 있다.
보조 인덱스는 정렬까지 해주지는 않는다. 입력 순서대로 들어가 있다. 사실 당연한 게 보조 인덱스는 여러 개 있을 수 있기 때문에 여러 정렬 조건을 적용할 수는 없다...
06 - 2 인덱스의 내부 작동
1. 균형 트리(Balanced tree)
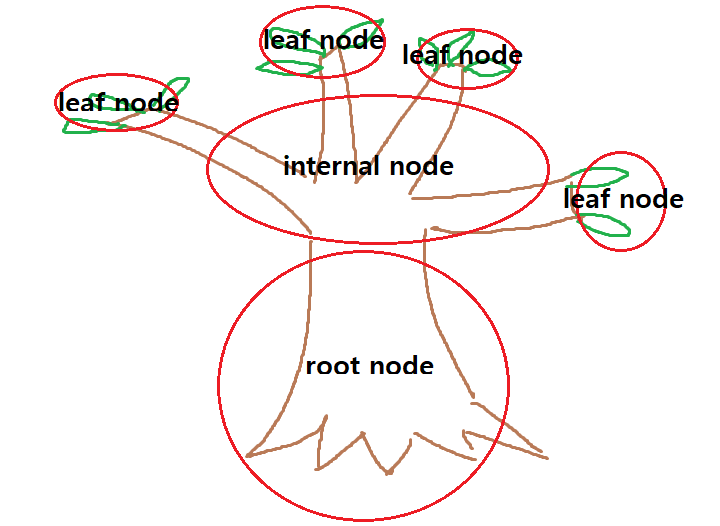
- 루트, 중간, 리프로 이루어진 자료구조. 트리 자료구조를 들어본 적 없다면 따로 공부해 보는 것이 좋을 것 같다. 알고리즘 문제에서 정말 많이 사용되기 때문이다. 따라서 나는 트리구조에 대해 알고 있음을 전제로 정리할 것이다.
- 데이터가 저장되는 공간을 노드(node)라고 한다.
루트 노드(root node): 가장 상위 노드. 출발 노드.
리프 노드(leaf node): 제일 마지막에 존재하는 노드.
중간 노드(internal node): 중간 단계의 노드.
2. 인덱스 내부 작동 원리
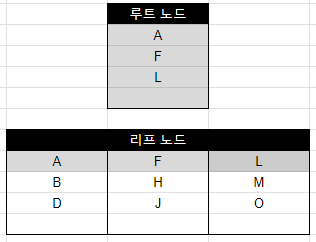
- 인덱스는 내부적으로 균형 트리의 형태로 구성된다.
- MySQL 에서는 노드를 페이지(page)라고 부른다. 페이지는 최소한의 저장 단위로 16KB의 크기를 가진다. (즉 한 건의 데이터만 입력해도 1 페이지가 생기기 때문에 16KB가 소모된다. 예제는 간단하게 표현하기 위해 최대 4개의 데이터가 들어가는 것으로 표현.)
- 인덱스가 없으면 모든 페이지를 검색해서 원하는 데이터를 찾아내지만, 인덱스는 루트 노드에서 다음 단계 노드들의 첫 번째 데이터를 가리키고 있기 때문에 훨씬 적은 페이지를 읽어도 된다.
3. 페이지 분리
- 인덱스는 SELECT의 속도를 향상하지만 데이터 변경 작업(INSERT, UPDATE, DELETE) 시에는 오히려 느려진다. 페이지 분할이라는 작업이 발생하기 때문.
- 페이지 분리는 한 페이지가 꽉 차서 데이터가 더 들어갈 수 없을 때 발생한다.
예시
1. I 입력
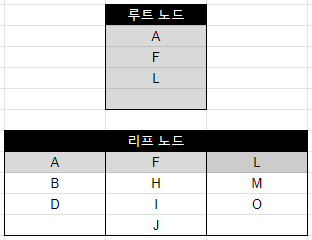
예시의 데이터는 한 페이지 당 4개가 들어갈 수 있기 때문에 사전순으로 I를 넣어도 페이지를 분리할 필요가 없다.
2. G 입력
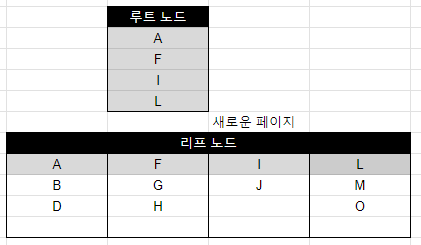
그런데 G를 입력하려다 보니 문제가 발생했다.
F와 H 데이터 사이에 입력되어야 할 텐데 데이터가 4개를 넘어가 버렸다. 이 때는 새로운 페이지를 만들어 데이터를 균등하게 분배한다. 이게 바로 페이지 분리 작업이다.
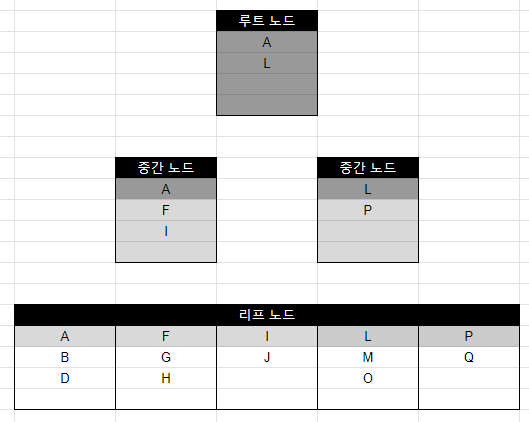
여기서 P와 Q를 또 입력하려고 하면 루트 페이지 공간도 부족해져 중간 페이지와 새로운 루트 페이지가 생성된다.
이러한 이유로 데이터 변경(특히 INSERT) 작업이 느려지는 것이다.
3. 인덱스의 구조
- 클러스터형 인덱스: 데이터 페이지가 인덱스에 포함됨.
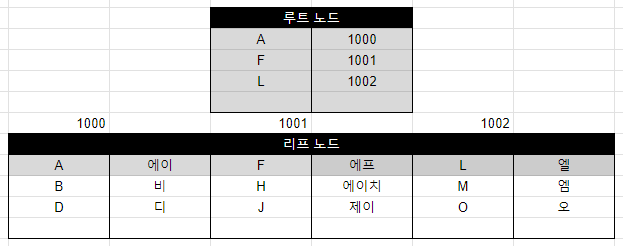
루트 페이지에는 리프 페이지에 대한 정보가 들어가 있다. 리프 페이지는 데이터 그 자체. 즉 클러스터형 페이지는 데이터 페이지를 직접 건드리게 되며 그 자체 인덱스로 사용하기 위해 정렬이 되는 것이다.
- 보조 인덱스: 데이터 페이지는 인덱스에 포함되지 않음. 대신 주소를 보고 찾아감.
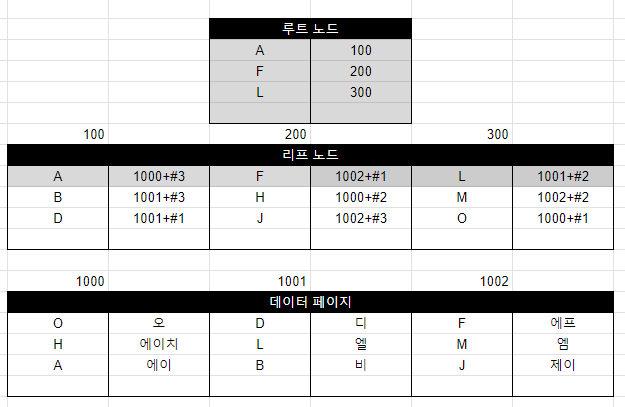
보조 인덱스의 리프 페이지는 데이터가 직접 대신 들어가는 대신, 해당하는 데이터의 주소가 들어가 있다. 이는 페이지 번호 +#위치로 기록되어 있다. 즉 데이터까지 찾아가기 위해 거쳐야 하는 과정이 좀 더 많은 것.
그래서 보조 인덱스가 클러스터형 인덱스에 비해 검색 시간이 조금 더 오래 걸린다.
06 - 3 인덱스의 실제 사용
1. 인덱스 생성, 제거
- 기본 키, 고유 키를 통해 자동으로 인덱스를 생성하는 것 이외에 CREATE INDEX 문을 통해 직접 생성하는 것도 가능하다. 이렇게 생성되는 인덱스는 모두 보조 인덱스이다.
- 생성
CREATE [UNIQUE] INDEX 인덱스_이름
ON 테이블_이름 (열_이름) [ASC | DESC]
UNIQUE는 중복이 안 되는 고유 인덱스를 만드는 것이다. 생략하면 중복이 허용된다.
ASC, DESC를 통해 오름차순, 내림차순 중 하나로 결정한다. 기본적으로 ASC로 만들어진다.
우선 인덱스를 만들어보기에 앞서 현재 member 테이블에 어떤 인덱스가 설정되어 있는지 보자.
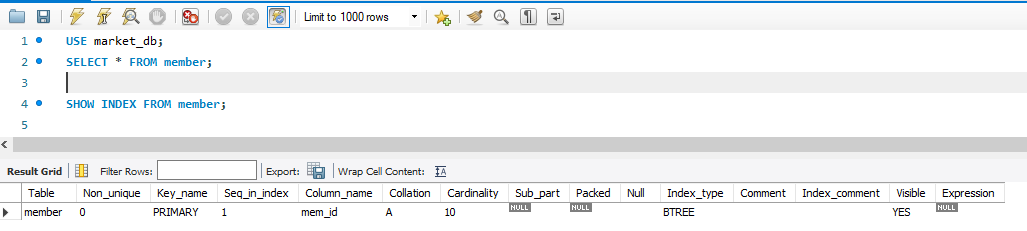
SHOW INDEX는 테이블에 생성된 인덱스 정보를 보여준다.
예제에서는 id 열에 기본 키를 설정했었다.
여기서 Key_name이 PRIMARY라고 뜨면 기본 키 즉 클러스터형 인덱스라는 뜻.
현재는 한 개의 인덱스만 설정되어 있다.

SHOW TABLE STATUS로 데이터의 크기도 확인할 수 있다. 1페이지의 최소 단위인 16KB가 할당되어 있다.
인덱스의 크기는 0인데 이는 보조 인덱스의 크기를 나타내기 때문에 표기되지 않은 것이다.

방금 배운 구문을 이용해 보조 인덱스를 생성했다.
UNIQUE를 사용하지 않았기 때문에 단순 보조 인덱스(중복을 허용하는 인덱스)에 해당한다.
따라서 고유하지 않음을 나타내는 Non_unique에 1이 표시되어 있다.

다시 인덱스의 크기를 확인했지만 여전히 0인데 아직 인덱스가 실제로 적용되지 않았기 때문이다.
ANALYZE TABLE 문을 통해 먼저 테이블을 분석/처리해줘야 한다.

인덱스 크기도 1페이지의 크기인 16KB가 되었다!
- 제거
DROP INDEX 인덱스_이름 ON 테이블_이름
참고로 고유 키, 기본 키로 자동 생성된 인덱스는 DROP INDEX로 제거할 수 없다.
이런 인덱스들은 ALTER TABLE 문으로 키를 제거해야 한다.
그리고 보조 인덱스를 모두 삭제한 뒤 클러스터형 인덱스를 제거하는 것이 좋다.
만약 클러스터형 인덱스가 제거되지 않는 경우에는 연결된 테이블에 외래키가 있는지 찾아보고 먼저 삭제하자.
information_schema.referential_constraints라는 문장을 통해 외래 키의 이름을 알아낼 수 있다.
- 주의할 점
유니크 인덱스로 만든다면 고유 키로 설정한 것이 아닌데도 중복된 값을 입력할 수 없다.
2. 인덱스를 사용하는 경우 & 사용하지 않는 경우
- INDEX는 WHERE 절에서 사용한다.
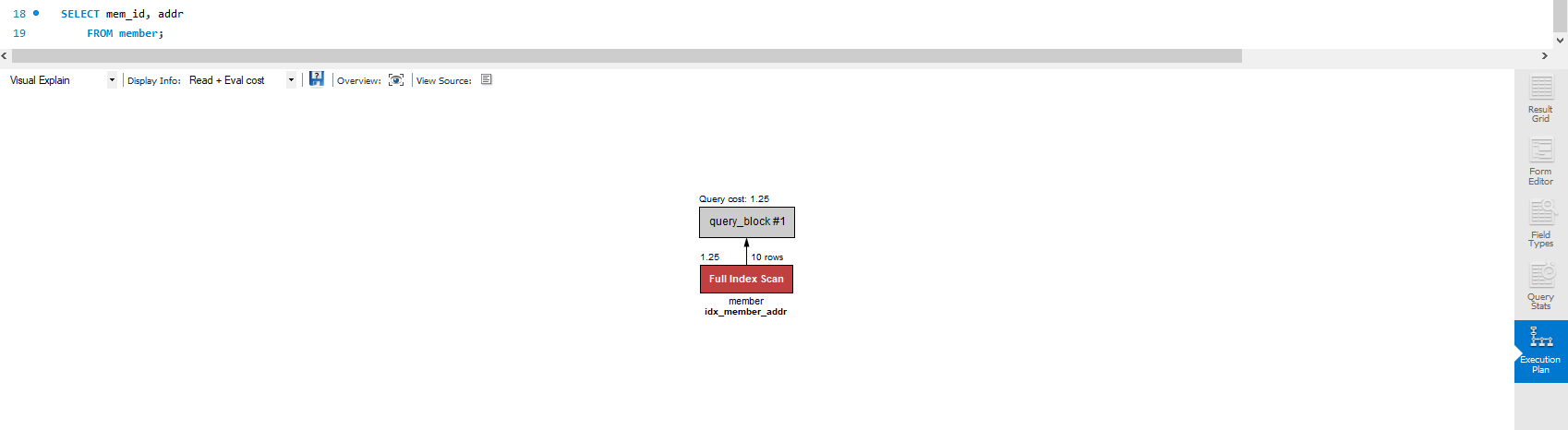
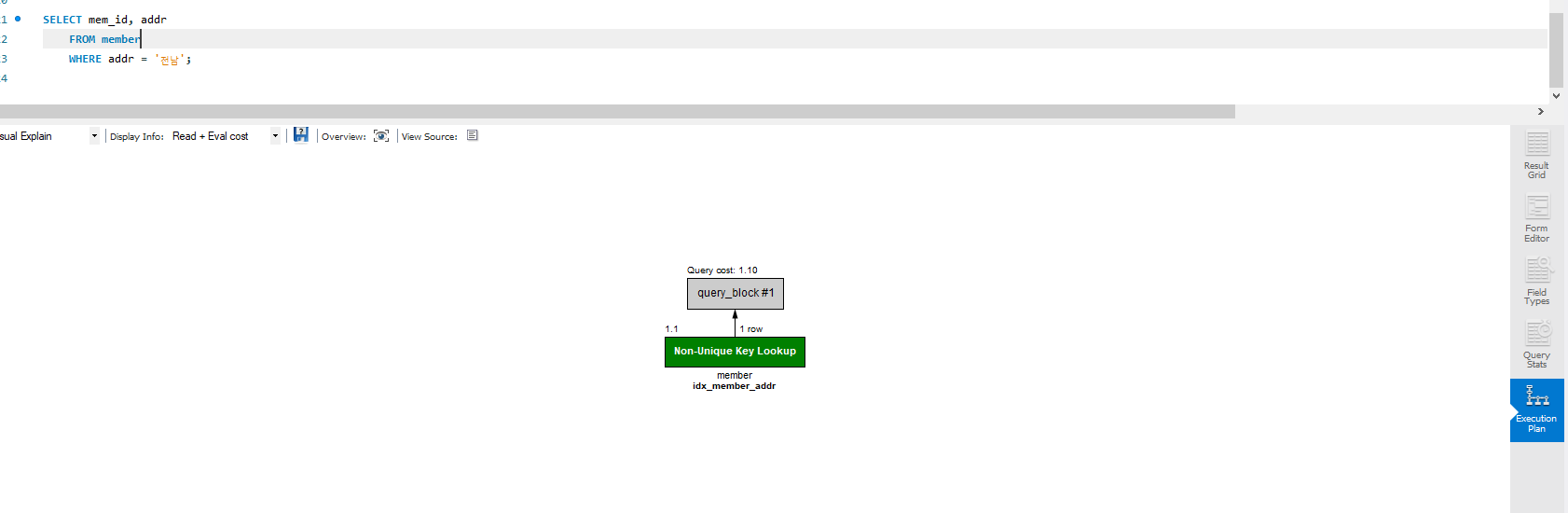
사실 여기서 나는 Full Table Scan이 아닌 Full Index Scan이 떴다. 교재에서는 Full Table Scan인데 name 인덱스는 생성하지 않아서 그런가? 찾아봐도 잘 모르겠다. 어찌 되었든 찾는 방식이 모든 범위를 찾는 것에서 인덱스를 활용하는 것으로 바뀌었다는 걸 알 수 있다.
- MySQL이 판단할 때 효율적이어야만
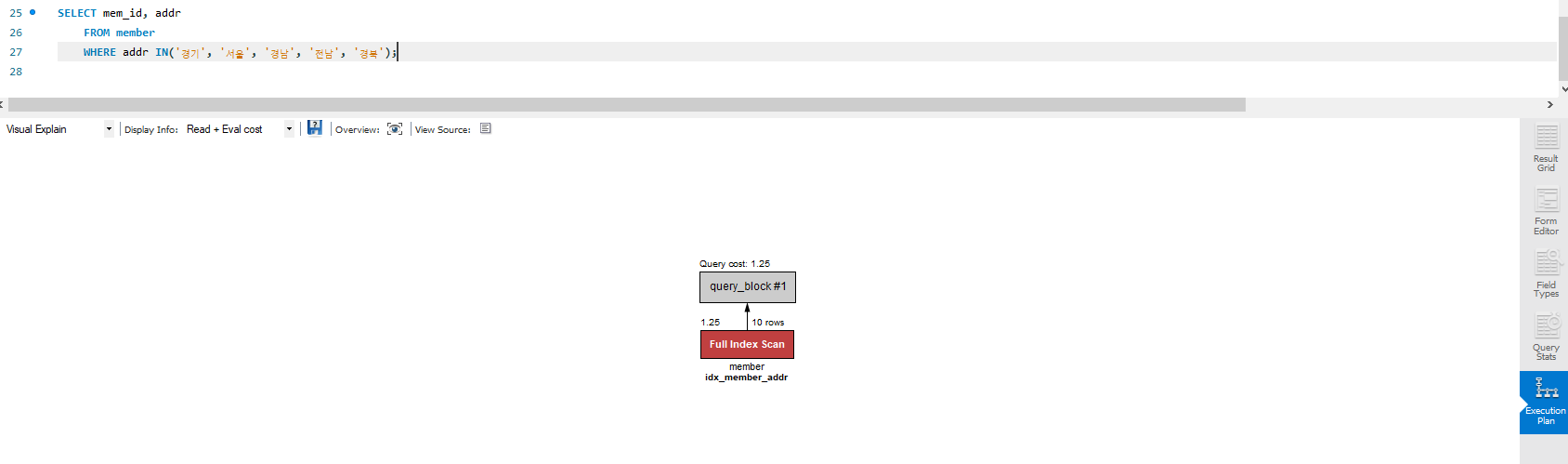
WHERE 절에 사용하더라도 항상 인덱스를 스캔하는 건 아니다.
이렇게 모든 테이블이 나올 수밖에 없을 땐 전체 테이블을 스캔하는 것이 빠를 것이다.
- 열에 연산을 가했을 때
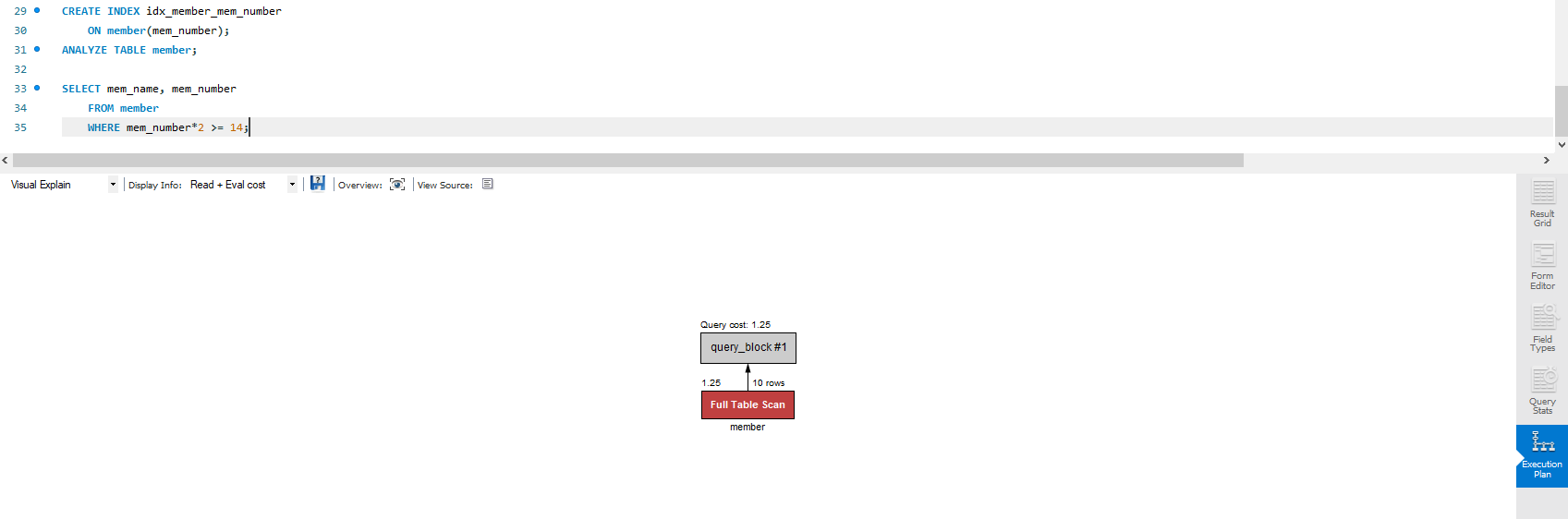
mem_number 열을 생성했음에도 불구하고 열에 연산을 가했더니 전체 테이블을 스캔했다.
그런데 이번엔 교재 예제랑 똑같이 해서 그런가 또 Full Table Scan이다. 아무래도 인덱스 스캔 기준을 명확하게 알아볼 필요가 있을 것 같다ㅠㅠ
이전 글 보기
1주 차
https://mountain-noroo.tistory.com/94
혼공학습단 11기 - 혼공S (1주차)
혼자 공부하는 SQL # 진도 기본 미션 선택 미션 1주차 (1/2 ~ 1/7) Chapter 01 ~ 02 p. 80의 shop_db의 회원 테이블(member)에서 아이유 회원에 대한 정보만 추출한 후 결과 화면 인증하기 데이터베이스 개체 3가
mountain-noroo.tistory.com
2주 차
https://mountain-noroo.tistory.com/97
혼공학습단 11기 - 혼공S (2주차)
혼자 공부하는 SQL # 진도 기본 미션 선택 미션 1주차 (1/2 ~ 1/7) Chapter 01 ~ 02 p. 80의 shop_db의 회원 테이블(member)에서 아이유 회원에 대한 정보만 추출한 후 결과 화면 인증하기 데이터베이스 개체 3가
mountain-noroo.tistory.com
'공부 기록 > 혼공학습단' 카테고리의 다른 글
| 혼공학습단 12기 - 혼공네트 (1주차) (0) | 2024.11.06 |
|---|---|
| SQLD 시험 후기 +a (0) | 2024.03.10 |
| 혼공학습단 11기 - 혼공S (4주차) (2) | 2024.01.25 |
| 혼공학습단 11기 - 혼공S (3주차) (1) | 2024.01.25 |
| 혼공학습단 11기 - 혼공S (2주차) (0) | 2024.01.12 |